End-to-End Database Implementation
Building a fully operational database system from the ground up – from schema design and data population to live operations, reporting, and NoSQL integration.
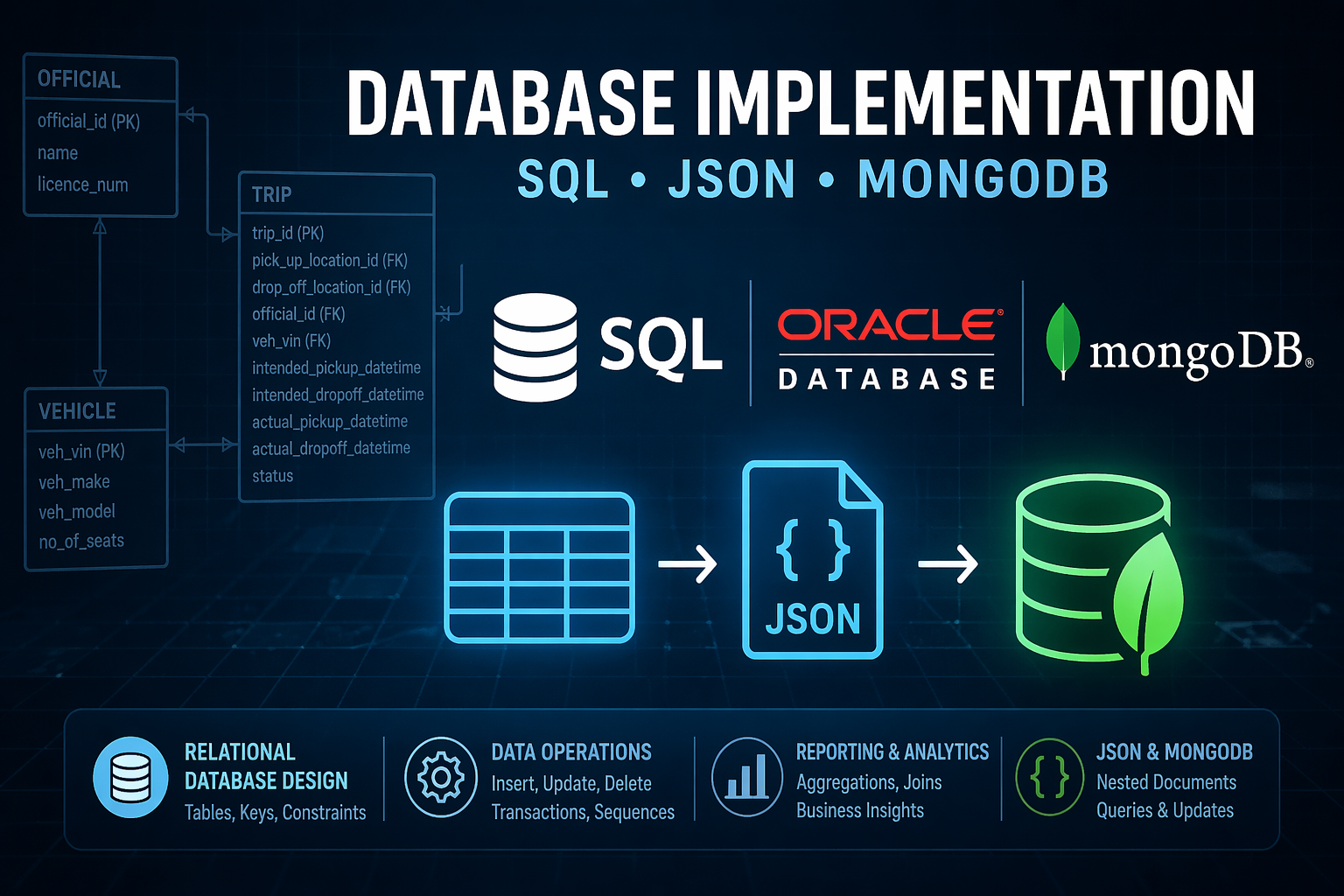
What is this project?
Picture the logistics behind a major international sporting event. Thousands of officials from over 200 countries need coordinated ground transport across an entire city – the right vehicle, the right driver, the right location, at the right time. Every booking, every trip update, every cancellation has to be tracked reliably. This project is the database system that makes all of that possible.
The scenario is Paris Arrow Transit (PAT), a fictional transport company subcontracted to manage official vehicles during the Olympic Games. Rather than designing the system from a blank page, the starting point was a provided data model – the conceptual blueprint of how the data should be structured. The task was to take that blueprint and build everything else: the tables, the relationships, the rules, the data, the operations, the reports, and finally a translation of the entire dataset into a completely different kind of database.
The result is a full end-to-end implementation covering the entire lifecycle of a relational database system, from its first line of schema code to live querying in MongoDB.
Why this project?
Databases are the invisible infrastructure underneath almost every digital system in existence. Every airline booking, every hospital record, every payroll run, every e-commerce transaction – all of it sits on top of a database. Most people who interact with data only ever see one slice of that picture: writing queries, or loading data, or building reports. This project was an opportunity to work through the entire thing in sequence, making deliberate decisions at every stage and seeing how each one affects what comes next.
The transport logistics scenario also made the work feel grounded. These were not abstract tables of dummy values – they represented officials with names and countries, vehicles with real-world attributes, trips with intended and actual times, drivers with language skills and suspension flags. Working with data that tells a story makes it considerably easier to reason about what the system should and should not allow.
How it came together
Laying the foundation
Before any data can be stored, the structure has to exist. This first stage involved defining every table in the system – what columns each one holds, what data types those columns accept, which fields are required versus optional, and how tables connect to one another through relationships. For PAT, this meant building out three core tables: OFFICIAL, VEHICLE, and TRIP. Officials needed to be linked to their country and to their team manager through a self-referencing relationship, where one official points back to another as their Chef de Mission.
Trips needed to connect simultaneously to officials, drivers, vehicles, pickup locations, drop-off locations, and a preferred language – each through a properly enforced foreign key constraint. Getting the constraints right matters more than it might seem. A foreign key does not just link two tables; it prevents the database from ever holding data that references something that does not exist. A uniqueness constraint on a trip ensures you cannot accidentally double-book the same vehicle and driver for the same timeslot. These rules are what make the database trustworthy rather than just functional.
Populating the System
With the schema in place, the next step was populating it with realistic test data – ten officials spread across multiple countries, ten vehicles across different model types, and twenty trips covering a range of scenarios: parallel bookings, multiple drivers, multiple languages, and vehicles appearing in more than one trip.
The data had to be internally consistent: drop-off times had to fall after pick-up times, vehicle passenger capacities had to match the number of passengers on each trip, and officials had to be correctly associated with their Chef de Mission. All inserts were wrapped in a single transaction and committed together, representing the initial state of the system before any live operations began.
Simulating Live Operations
From there, the database was run as if it were live. New records cannot simply be inserted with hardcoded ID numbers – in a real multi-user system, multiple people might be inserting records simultaneously, so primary keys are generated dynamically using sequences. The operational scenarios played out in sequence: registering a new official and vehicle, booking two trips as a single atomic transaction, then handling an unexpected event mid-day.
A driver completed her first trip but ran 15 minutes over schedule; later that afternoon she was involved in an accident. Every incomplete trip assigned to her for the rest of the day had to be identified and removed from the system – without hardcoding any IDs, using subqueries to look up the relevant values dynamically.
Evolving the Schema
Real databases do not stay static. Requirements change, and the schema has to evolve without breaking what already works or losing any existing data. Two structural changes were introduced mid-project. First, PAT wanted to track each official’s role – General, Administrator, Head Coach, Coach, or Physician – which required creating a new reference table, adding a foreign key column to the existing OFFICIAL table with a sensible default, and updating all Chef de Missions to the Administrator role.
Second, PAT wanted to support driver complaints, requiring two new tables to capture complaint categories with associated demerit points, and individual complaints linked to specific trips. All of this happened with other users assumed to be active in the system – no taking the database offline, no wiping and restarting.
Turning Data into Answers
Once the system was running and the data was solid, the focus shifted to extracting meaning from it. Two reporting queries were built. The first answered a location usage question: across all completed trips, which pickup and drop-off locations were used most frequently?
This required combining two separate counts using a UNION, then joining back to the location tables to produce a readable, ordered report. The second was a payroll report covering a specific week, calculating each driver’s total earnings based on the actual duration of their completed trips at a fixed hourly rate, with drivers who had no trips during the period displaying “No Trips” rather than a blank.
Crossing into NoSQL
The final stage stepped outside the relational model entirely. The same data that had been living in structured rows and columns was transformed into nested JSON documents and loaded into MongoDB. Where a relational database stores information in separate tables joined together at query time, MongoDB stores everything about a subject in a single document. A driver document here contained not just the driver’s name and licence number, but an embedded array of all their completed trips – each trip containing nested objects for the pickup and drop-off details.
The SQL-to-JSON transformation was done using Oracle’s JSON functions to assemble the nested structure directly from a query, before being inserted into MongoDB, queried by destination, and updated to reflect a newly discovered trip and a driver suspension. Working across both systems with the same underlying data makes the trade-offs between relational and document-based databases concrete in a way that reading about them simply does not.