Database Design for a Multi-Branch Library System
Translating real-world library operations into a fully normalised relational database – from business requirements to a production-ready Oracle SQL schema.
What is this project?
A community library network operating across multiple locations sounds straightforward on the surface. But look closely and the complexity reveals itself quickly. Each branch holds its own physical copies of books, but the catalogue is shared across all of them. A borrower registered at one branch might reserve a copy held at another. A single title can have multiple editions, each with its own ISBN. Fines accumulate on overdue loans and need to be tracked and cleared. Borrowers have classifications that govern what they can and cannot borrow.
This project is the database that makes all of that manageable. Starting from a set of written business requirements for a fictional library network called ReadMore Community Library, the task was to design a relational database system from the ground up – building a conceptual model, normalising the data, producing a logical design, and finally implementing a full Oracle SQL schema with constraints, keys, and business rules enforced at the database level.
There is no dashboard here, no live queries, no operational scripts. The deliverable is the design itself – a structured, scalable system that a real library could build on.
Why this project?
Database design is a discipline that sits upstream of everything else. Before anyone writes a query, before any application reads or writes data, someone has to make a set of decisions about how that data is structured – what belongs in its own table, what gets linked, what gets enforced, and what gets left flexible. Those decisions have consequences that compound over time. A poorly designed schema is painful to query, difficult to extend, and prone to inconsistency. A well-designed one feels almost invisible.
This project was an opportunity to work through that entire upstream process deliberately and carefully, with a scenario complex enough to surface real design challenges. A library system has just enough variety – books, copies, borrowers, loans, reservations, branches, managers, authors, subjects, publishers – to require thoughtful modelling without becoming unmanageable. Every decision made here maps directly to the kind of thinking required in any serious data engineering or analysis role.
How it came together
Understanding the Requirements
The starting point was a written description of how ReadMore Community Library operates – its branches, its catalogue, its borrowers, and its loan and reservation workflows. Before any modelling could begin, that description needed to be read carefully and translated into a clear picture of the entities involved, the relationships between them, and the rules the system would need to enforce.
Several assumptions had to be made explicit at this stage. The library catalogue is shared across all branches, meaning a borrower at any branch can see and reserve the same titles. An LGA code is only recorded when a branch exists in that area. A branch can operate without a manager assigned. Fines are recorded against loans and paid on the day the overdue book is returned. These assumptions shaped every design decision that followed, so documenting them clearly was as important as the modelling itself.
Conceptual Modelling
The first formal output was an entity-relationship diagram – a high-level map of the key entities in the system and how they relate to one another. At this stage the focus is on what exists and how things connect, not yet on how those connections will be implemented in a database.
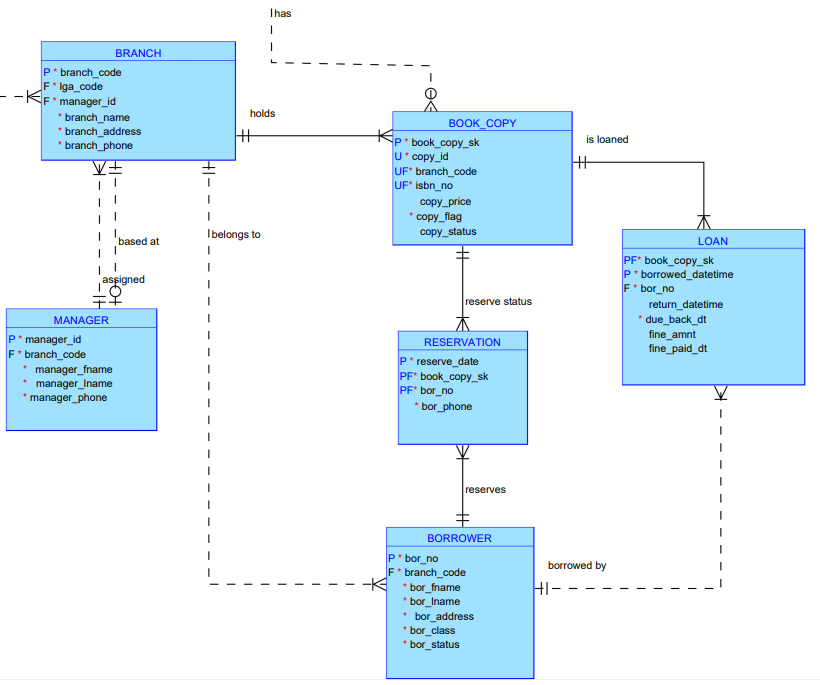
The core entities identified were branches, managers, borrowers, catalogue entries, books, book copies, loans, and reservations. A branch belongs to a Local Government Area and is assigned a manager. Borrowers are registered at a home branch. The catalogue holds title-level information shared across all branches. Physical book copies are held at specific branches and linked to ISBN-level records. Loans and reservations connect borrowers to specific physical copies.
One relationship that required careful thought at this stage was between a branch and its manager. A manager is based at a branch, but a branch can exist without a manager – meaning the relationship needed to be optional on one side. Getting cardinality right at the conceptual stage prevents structural problems from propagating into every stage that follows.
Normalisation
With the conceptual model in place, the next step was normalisation – a formal process for eliminating redundancy and ensuring that data is stored in the most structured, dependency-correct form possible.
The process started from Unnormalised Form (UNF), where data arrives as it might appear in a flat document or spreadsheet – repeating groups, mixed granularity, and hidden dependencies all mixed together. A catalogue search result, for example, might list a title alongside multiple authors, multiple subjects, and multiple publishers all in a single row. A borrower loan report might embed multiple loan records inside a single borrower row.
Working through UNF to First Normal Form (1NF) meant removing repeating groups and ensuring every field held a single value. Moving to Second Normal Form (2NF) meant identifying and eliminating partial dependencies – cases where an attribute depended on only part of a composite key rather than the whole thing. In the loan data, for instance, branch name was found to depend only on branch code rather than on the full composite key, so it was separated out. Third Normal Form (3NF) addressed transitive dependencies – attributes that depended on other non-key attributes rather than directly on the primary key.
By the end of this process, the data had been decomposed into a clean set of relations: CATALOGUE_ENTRY, AUTHOR, AUTHOR_CATALOGUE, SUBJECT, SUBJECT_CATALOGUE, PUBLISHER, PUBLISHER_CATALOGUE, BOOK, BOOK_CATALOGUE, BORROWER, BRANCH, and LOAN – each with a clear primary key and no redundant dependencies.
Logical Design
The logical model took the normalised relations and refined them into a full relational schema, resolving complexities that normalisation alone does not handle and introducing structures needed for the system to actually function.
The most significant design challenge was the many-to-many relationships. A catalogue entry can be written by multiple authors, and an author can write multiple catalogue entries. The same applies to subjects and publishers. Each of these was resolved using a bridge table – AUTHOR_CATALOGUE, SUBJECT_CATALOGUE, and PUBLISHER_CATALOGUE – linking the two sides of the relationship through a composite primary key.
A more subtle but consequential decision was the separation of BOOK and BOOK_COPY. A BOOK record represents an ISBN – a specific edition of a title – while a BOOK_COPY record represents a physical item sitting on a shelf at a particular branch. This distinction matters enormously in practice. A library might hold six physical copies of the same ISBN across three branches. Loans and reservations are made against physical copies, not against the abstract ISBN. Collapsing these two concepts into a single table would make it impossible to track inventory accurately.
The BOOK_COPY table presented a further challenge: its natural primary key was a composite of branch code and copy ID, since copy IDs are only unique within a branch. But using a composite key as the target of foreign key references in the LOAN and RESERVATION tables would have made those relationships unnecessarily complex. The solution was to introduce a surrogate key – book_copy_sk – a single synthetic identifier for each physical copy that simplifies all downstream relationships without losing any information.
Schema Implementation
The final stage was translating the logical model into a working Oracle SQL schema. Every table from the logical design was implemented with its full set of constraints – primary keys, foreign keys, unique constraints where required, and CHECK constraints to enforce business rules directly at the database level.
Business rules encoded into the schema included restrictions on borrower classification values, permitted book types (paperback, loose leaf, and hardcover), copy status flags, and the relationship between fine amounts and return dates. Enforcing these rules in the schema rather than relying on application-level validation means they hold regardless of how the data is accessed or modified – a core principle of robust database design.
Column-level comments were added throughout to document the purpose of each attribute, making the schema self-describing for anyone working with it in future. The schema was verified by running it in full and confirming clean execution with no constraint violations.